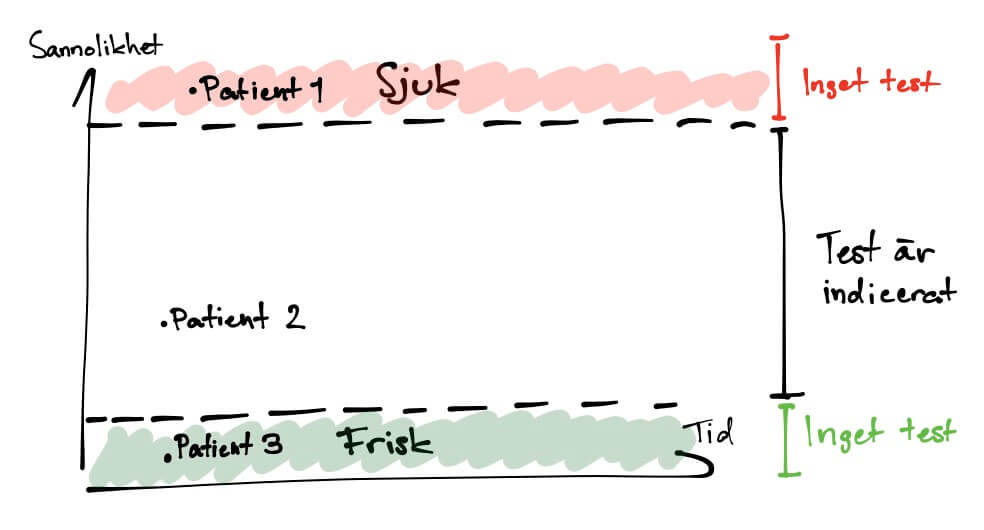
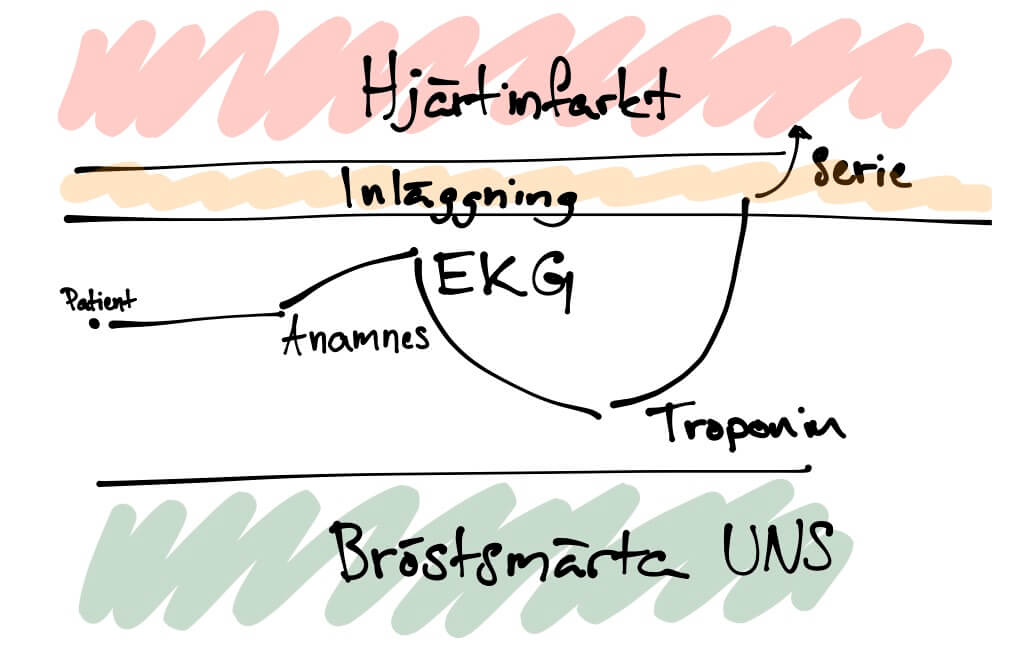
Här är del nummer två om hur man värderar ett test. Del nummer ett hittar ni här och handlade om hur man tolkar sensitivitet, specificitet samt negativt och positivt prediktivt värde för olika test. Hela artikelserien om diagnostik finns här. I den här delen skall vi gå igenom likelihood ratios, ett praktiskt användbart sätt att tolka ett testresultat. Jag kommer också försöka ge ett praktiskt exempel varför det är viktigt att förstå skillnader mellan alla dessa termer.
Innehåll
Likelihood ratios (LR)
Det finns inget vedertaget svenskt namn för detta utan man brukar använda detta engelska varianten och man pratar om negativ LR (LR-) och positiv LR (LR+). Med Sens/Spec kunde vi inte säga så mycket om vår patient framför oss när vi använder ett test, de talar bara om sannolikheten för positivt/negativt test utifrån baserat på om patienten är sjuk eller inte. NPV/PPV utgår utifrån gruppen patienter och dess prevalens uppskatta hur stor sannolikhet det är att en enskild patient är sjuk. Med LRs kan vi utifrån patientens individuella risk (Pre-test probability) räkna ut sannolikheten för att den är sjuk utifrån ett positivt eller negativt test. Detta är därför på många sätt det mest användbara instrumentet när man jobbar. Men kräver också mer information och tankeverksamhet.. Man räknar ut LR+ och LR- enligt följande:
Positiv Likelihood Ratio (LR+) = Sensitivitet / (1 – Specificitet)
Negativ Likelihood Ratio (LR-) = (1 – Sensitivitet) / Specificitet
LR+ och LR- är ration (förändringen) med vilken sannolikheten för sjukdom ökar eller minskar beroende på ett testresultat. För att veta sannolikheten för sjukdom efter ett test behöver vi då veta sannolikheten för sjukdom inför ett test . Ett LR+ > 1 ökar sannolikheten för sjukdom vid ett positivt test och ett LR- < 1 minskar risken för sjukdom vid ett negativt test. Som tumregel skall ett test helst ha ett LR+ > 10 eller LR- < 0.1 för att ett test skall vara riktigt användbart.
För att enkelt använda Likelihood ratios finns sannolikhetsdiagram eller normogram.
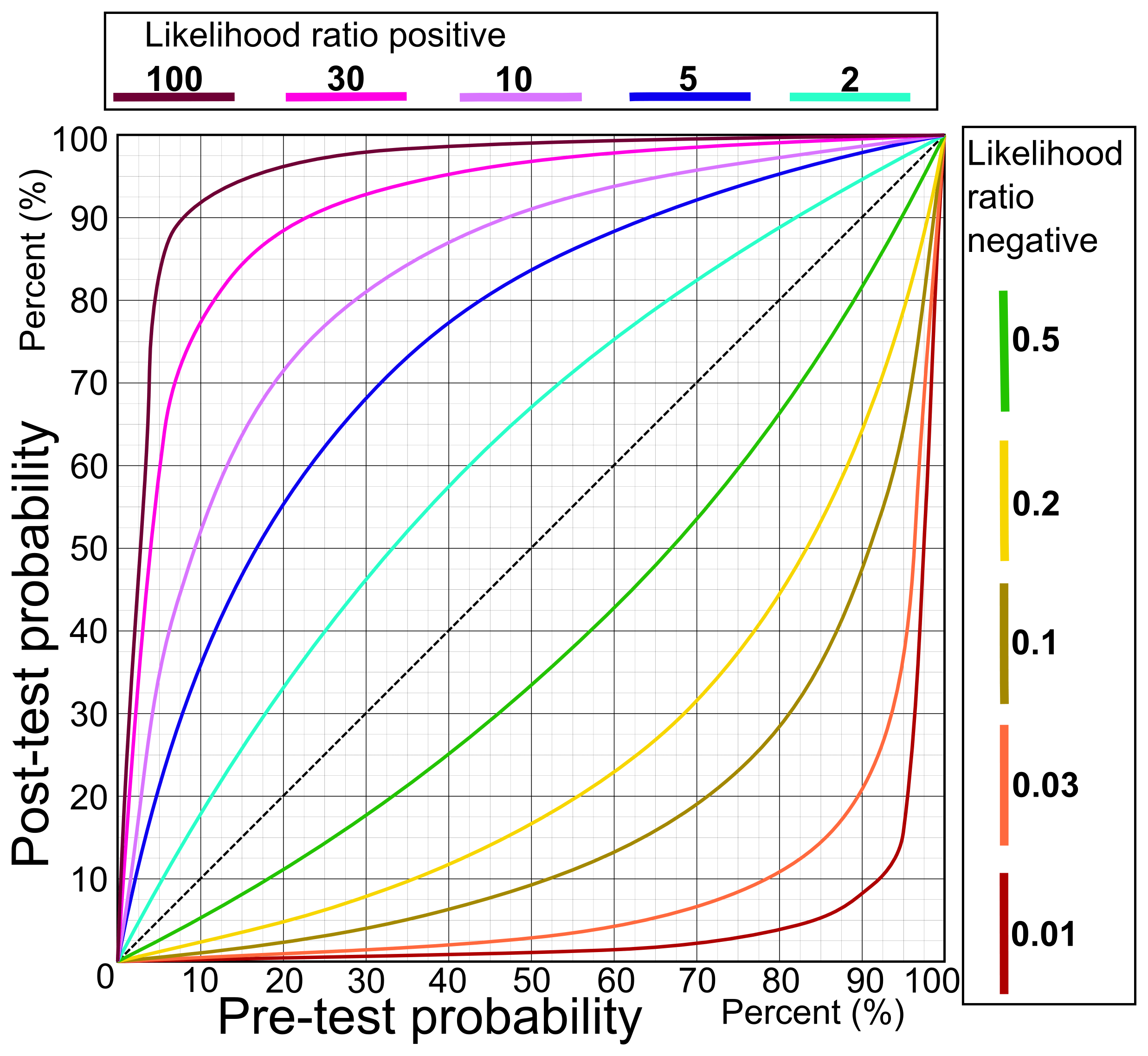
Post test probability är beroende av Pre test probability
Här kan man se hur sannolikheten för sjukdom förändras efter ett negativt (orange) eller positivt (rosa) resultatet. Hur den gröna och röda kurvan ser ut beror på hur hög respektive låg LR+/LR- testet har. Låt oss säga att du har en patient med bröstsmärta som du misstänker har en 10% chans att ha en hjärtinfarkt (pre test probability). Detta enbart baserat på demografiska data (i europeiska material har ca 10-12% av patienter som söker med bröstsmärta hjärtinfarkt) utan några ytterligare försvårande riskfaktorer. Har du då ett test med en LR+ på 10 blir den post-test probability ca 52% (där lila linje skär 10% på ex-axeln). Får du ett negativt resultat på testet som har en LR- på 0.1 har du istället 1-2% risk att patienten har en hjärtinfarkt (brungul linje).
Det man ser i den här grafen är också att ett test hjälper olika mycket beroende på vilket pre-test probability vi har. Säg att vi har en patient med hög risk för sjukdom (t.ex. 70%). Ett positivt svar på ett test med LR+ 10 tar oss från 70% till 96%. Det är fortfarande ganska mycket men inte lika mycket som vid den lägre sannolikheten (10% till 52%).
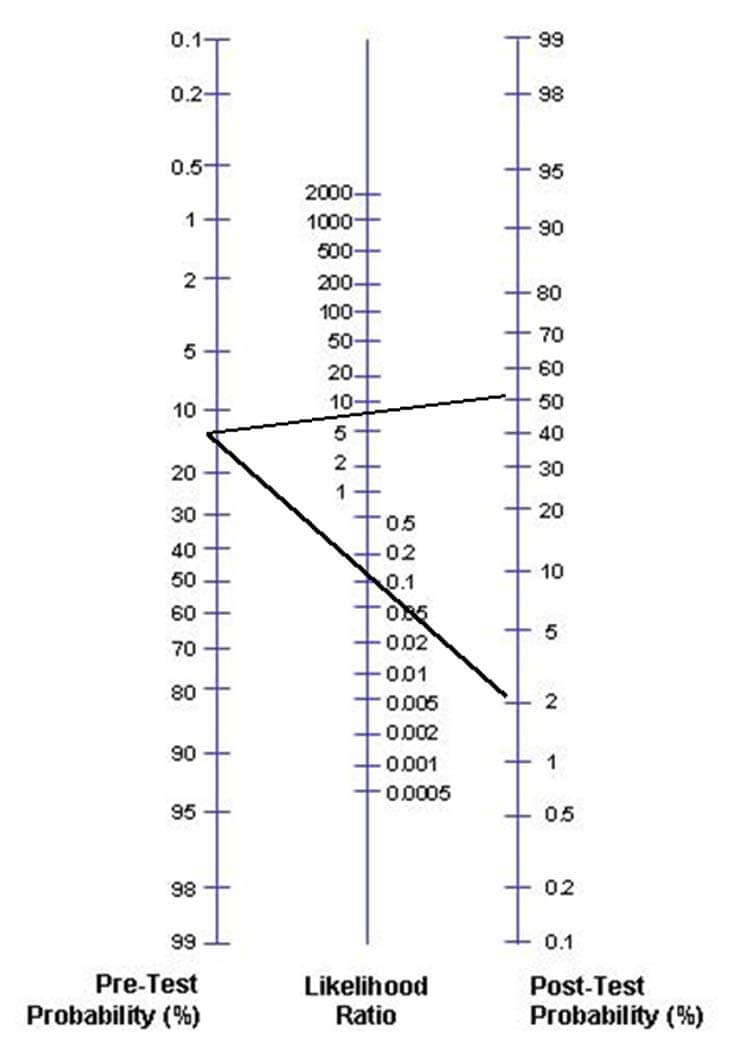
Likelihood ratio nomogram
Med ett normogram för likelihood ratios kan man med en likelihood ratio och pre test probability räkna ut post test probability. Man drar då ett rakt streck från sin pre test probability på vänster sida, genom LR+/LR- för sitt test till en post test probability.
It takes two to Tango
Det är dock så att Sensitivitet och Specificitet inte är oberoende av varandra. Har man ett test med bra sensitivitet men väldigt dålig specificitet skall man inte förledas att tro att man bara kan titta på testets sensitivitet och använda testet för att “utesluta” sjukdom. Om vi räknar ut LRs utifrån sensitivitet och specificitet ser vi ett intressant mönster.
| Sens | Spec | LR+ | LR- |
| 90 | 10 | 1 | 1 |
| 90 | 30 | 1 | 0.3 |
| 90 | 50 | 1.8 | 0.2 |
| 90 | 70 | 3 | 0.14 |
| 90 | 80 | 4.5 | 0.13 |
Ett test med hög sensitivitet har ganska värdelös LR- (=dålig på att minska patientens sannolikhet för sjukdom om testet är negativt). När specificiteten förbättras börjar vi närma oss gränsen för vad som är ett bra “uteslutande test” (LR- < 0.1). Som riktmärke kan man ha att ju närmare summan av Sens + Spec är 1 (eller 100%), desto mer värdelöst är testet. Om Sensitivitet är 0.99 (99%) och specificiteten är 0.01 (1%) kommer LR- fortsatt att vara 1 (=testet hjälper oss inte så mycket).
Varför är allt detta viktigt att veta?
Har man en frisk grupp med endast några få som har sjukdomen (t.ex. Bröstsmärta vid misstanke om ischemisk hjärtsjukdom) så kommer de flesta test hitta de få sjuka patienterna och därigenom få en hög sensitivitet. Däremot kan det vara flera som får falskt positiva värden, klassas som sjuka och därigenom får testet en lägre specificitet. Motsatta resultat sker om man har en grupp med hög sjuklighet istället då sensitiviteten sjunker men specificiteten ökar.
När man tittar på ett tests prestanda är det därför viktigt att veta vilken grupp människor den har testats på och hur väl den gruppen överensstämmer med de patienter som man själv använder testet på. Historiskt så görs mycket forskning i USA där man har en patientpopulation på sina akutmottagningar som ofta har en lägre underliggande risk.
Exempel: Pulmonary Embolism Rule out Criteria (PERC)
Ett bra exempel på när ovanstående blir ett potentiellt kliniskt problem såg vi när man tog fram PERC, ett beslutsstöd för att riskstratifiera patienter med risk för lungemboli(LE) [1].
Historiskt har man i USA haft en underliggande prevalens för LE på akutmottagningar som legat på mellan 3-5%. Det vill säga hos alla patienter som man bedömde att det fanns en risk för lungemboli så hade mellan 3-5% en faktiskt lungemboli. Man tog fram PERC-stödet som skulle hjälpa läkare att ta bort patienter som hade mindre än 2% risk för lungemboli. Under 2% sannolikhet började riskerna med fortsatta test, behandling, strålning etc bli farligare för patienten än risken för lungemboli [1]. Studierna på PERC gick väldigt bra och fick bra genomslag i USA.
När man sedan ville börja använda PERC i Europa insåg man att Europeiska studier visar på att man har en prevalens på LE på mellan 10-15% (upp emot 20%) för LE i dem grupperna som man misstänker LE i. Detta beror inte på att man har mer patienter lungemboli i Europa utan att man sannolikt har en lite högre selekterad grupp av patienter och en högre tröskel för att misstänka LE [2].
I och med olikheterna beslutade man sig för att göra kliniska studier på PERC-stödet även i Europa för att se till att testet presterade lika bra i en annan grupp. Man var orolig för att sensitiviteten blev sämre med en sjukare grupp patienter. Tillslut utmynnade i att man även här kan använda det med lika bra säkerhet här som i USA [3].
Sammanfattning
Diagnostiska testers prestanda beskrivs på olika sätt och man kan i olika situationer behöva använda olika värden i olika situationer.
- Sensitivitet och Specificitet: ger bra uppfattning om generell prestanda för ett test och är grunden för att räkna ut prediktiva värden och Likelihood ratios, men hjälper dig inte när du står men en patient och har ett testresultat. Ett test där summan av Sens+Spec är 1 eller nära 1 är mer eller mindre värdelöst. Ju närmare 2 desto bättre.
- Negativt och Positivt prediktivt värde: Liknar sensitivitet och specificitet men tar hänsyn till prevalensen av sjukdomen. Ger en mer rättvis bild och går att använda kliniskt.
- Likelihood ratios: Talar om för oss vad som händer med sannolikheten för sjukdom hos en enskild patient, där vi gjort en riskstratifiering innan vi har vårt testresultat. Är bäst lämpat för att tolka ett testresultat för en enskild patient.
Mer att läsa om detta kan göras på pulmcrit som också varit inspiration till detta inlägget.
Pre-publication review: Michael von Schickfus, Specialist i Akutsjukvård
Referenser
- Kline, Mitchell, Kabrhel, Richman, Courtney. Clinical criteria to prevent unnecessary diagnostic testing in emergency department patients with suspected pulmonary embolism. J Thromb Haemost 2004;2:1247–55.
- Hugli O, Righini M, Le Gal G, Roy P-MM, Sanchez O, Verschuren F, et al. The pulmonary embolism rule-out criteria (PERC) rule does not safely exclude pulmonary embolism. J Thromb Haemost 2011;9:300–4.
- Singh B, Mommer S, Erwin P, Mascarenhas S, Parsaik A. Pulmonary embolism rule-out criteria (PERC) in pulmonary embolism—revisited: A systematic review and meta-analysis. Emerg Med J 2012;30:701–6.